自動微分 (じどうびぶん、英 : automatic differentiation, autodiff, AD )やアルゴリズム微分 (英 : algorithmic differentiation )とは、プログラムで定義 された関数を解析 し、関数の値と同時に偏導関数 の値を計算するアルゴリズム である。
自動微分は複雑なプログラムであっても加減乗除などの基本的な算術演算や基本的な関数(指数関数 ・対数関数 ・三角関数 など)のような基本的な演算の組み合わせで構成されていることを利用し、これらの演算に対して合成関数の偏微分の連鎖律 を繰り返し適用することによって実現される。自動微分を用いることで偏導関数値を少ない計算量で自動的に求めることができる。
図1: 自動微分と記号微分の関係 自動微分は以下のどちらとも異なる。
記号微分・数式微分(symbolic differentiation) - 原関数を表す数式から数式処理 により導関数を導出する。数式処理システムで実装されている。 数値微分(numerical differentiation) - 原関数の値から数値的に微分係数を算出する 記号微分は効率が悪くなりやすく、プログラムで定義された関数から微分表現を導くのは困難であるという問題がある。一方、数値微分では離散化の際の丸め誤差 や桁落ちによる精度の低下が問題である。さらに、どちらの手法も計算量や誤差の関係で高次の微分係数を求めることが難しい。また、勾配を用いた最適化で必要となる、多くの入力変数を持つ関数に対する偏微分値の計算を行うには速度が遅い。自動微分はこれらの古典的手法の問題を解決する。[ 1]
また、自動微分は計算フローを追いかけることで計算できるので、分岐(if文)やループや再帰を含むようなアルゴリズムでも偏微分できる[ 1]
自動微分の基本原理は、合成関数の偏微分 の連鎖律 を用いた偏微分の分解である。
合成関数の偏微分の連鎖律とは y = f ( w 1 , w 2 ) , w 1 = g ( x 1 , x 2 ) , w 2 = h ( x 1 , x 2 ) {\displaystyle y=f(w_{1},w_{2}),w_{1}=g(x_{1},x_{2}),w_{2}=h(x_{1},x_{2})} [ 2] [ 3]
∂ y ∂ x 1 = ∂ y ∂ w 1 ∂ w 1 ∂ x 1 + ∂ y ∂ w 2 ∂ w 2 ∂ x 1 {\displaystyle {\frac {\partial y}{\partial x_{1}}}={\frac {\partial y}{\partial w_{1}}}{\frac {\partial w_{1}}{\partial x_{1}}}+{\frac {\partial y}{\partial w_{2}}}{\frac {\partial w_{2}}{\partial x_{1}}}}
自動微分は2種類に分けられ、それぞれ
ボトムアップ型自動微分 (フォーワード・モード 、フォーワード・アキュムレーション 、タンジェント・モード 、狭義の自動微分 )トップダウン型自動微分 (リバース・モード 、リバース・アキュムレーション 、随伴モード 、高速自動微分 )と呼ばれる。
ボトムアップ型自動微分では連鎖律を内側から外側に計算し(∂w /∂x ∂y /∂w
使い分けは、入力が n 次元、出力が m 次元とした場合、以下の違いがある。
n < m ならばボトムアップ型の方が計算量が少ない。ボトムアップ型の計算回数はn回。 n > m ならばトップダウン型の方が計算量が少ない。トップダウン型の計算回数はm回。 機械学習 において、評価値はほぼ常に m = 1 の実数なので、トップダウン型が使われる。機械学習で用いられる多層パーセプトロン のバックプロパゲーション はトップダウン型自動微分の特殊なケースである。
ボトムアップ型はR.E. Wengertが1964年に発表したが、2ページの論文で特に名前を付けていない[ 4] [ 5]
ボトムアップ型自動微分では最初に偏微分を行う入力変数を固定し、それぞれの部分式を再帰的に計算する。手計算においては連鎖律において内側の関数を繰り返し置き換えていくことに相当する。
∂ y ∂ x = ∂ y ∂ w 1 ∂ w 1 ∂ x = ∂ y ∂ w 1 ( ∂ w 1 ∂ w 2 ∂ w 2 ∂ x ) = ∂ y ∂ w 1 ( ∂ w 1 ∂ w 2 ( ∂ w 2 ∂ w 3 ∂ w 3 ∂ x ) ) = ⋯ {\displaystyle {\frac {\partial y}{\partial x}}={\frac {\partial y}{\partial w_{1}}}{\frac {\partial w_{1}}{\partial x}}={\frac {\partial y}{\partial w_{1}}}\left({\frac {\partial w_{1}}{\partial w_{2}}}{\frac {\partial w_{2}}{\partial x}}\right)={\frac {\partial y}{\partial w_{1}}}\left({\frac {\partial w_{1}}{\partial w_{2}}}\left({\frac {\partial w_{2}}{\partial w_{3}}}{\frac {\partial w_{3}}{\partial x}}\right)\right)=\cdots } 多変数の場合はヤコビ行列 の積として一般化できる。
トップダウン型自動微分と比較すると、ボトムアップ型自動微分は自然であり、偏微分に関する情報の流れが計算の順序と一致するため簡単に実行できる。それぞれの変数にその偏導関数値 w ˙ i {\displaystyle {\dot {w}}_{i}}
w ˙ i = ∂ w i ∂ x {\displaystyle {\dot {w}}_{i}={\frac {\partial w_{i}}{\partial x}}} の計算値を保存する領域を付け加えるだけで、変数値の計算と同時に偏導関数値を計算することができる。
連鎖律より、 w i {\displaystyle w_{i}}
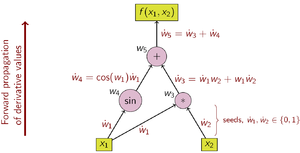
w ˙ i = ∑ j ∂ w i ∂ w j w ˙ j {\displaystyle {\dot {w}}_{i}=\sum _{j}{\frac {\partial w_{i}}{\partial w_{j}}}{\dot {w}}_{j}} 図2: ボトムアップ型自動微分の計算グラフの例 例として次の関数を考える。
y = f ( x 1 , x 2 ) = x 1 x 2 + sin x 1 = w 1 w 2 + sin w 1 = w 3 + w 4 = w 5 {\displaystyle {\begin{aligned}y&=f(x_{1},x_{2})\\&=x_{1}x_{2}+\sin x_{1}\\&=w_{1}w_{2}+\sin w_{1}\\&=w_{3}+w_{4}\\&=w_{5}\end{aligned}}} それぞれの部分式を中間変数 w i {\displaystyle w_{i}} w 1 = x 1 , w 2 = x 2 {\displaystyle w_{1}=x_{1},w_{2}=x_{2}}
どの入力変数で偏微分するかによって w ˙ 1 {\displaystyle {\dot {w}}_{1}} w ˙ 2 {\displaystyle {\dot {w}}_{2}} x 1 {\displaystyle x_{1}}
w ˙ 1 = ∂ w 1 ∂ x 1 = ∂ x 1 ∂ x 1 = 1 w ˙ 2 = ∂ w 2 ∂ x 1 = ∂ x 2 ∂ x 1 = 0 {\displaystyle {\begin{aligned}{\dot {w}}_{1}={\frac {\partial w_{1}}{\partial x_{1}}}={\frac {\partial x_{1}}{\partial x_{1}}}=1\\{\dot {w}}_{2}={\frac {\partial w_{2}}{\partial x_{1}}}={\frac {\partial x_{2}}{\partial x_{1}}}=0\end{aligned}}} となる。初期値が決まったら下の表に示す連鎖律に従って各偏導関数値を順に計算していく。図2はこの処理を計算グラフとして表している。 w ˙ 5 = ∂ y ∂ x 1 {\displaystyle {\dot {w}}_{5}={\tfrac {\partial y}{\partial x_{1}}}}
Operations to compute value Operations to compute derivative w 1 = x 1 w ˙ 1 = 1 (seed) w 2 = x 2 w ˙ 2 = 0 (seed) w 3 = w 1 ⋅ w 2 w ˙ 3 = w 2 ⋅ w ˙ 1 + w 1 ⋅ w ˙ 2 w 4 = sin w 1 w ˙ 4 = cos w 1 ⋅ w ˙ 1 w 5 = w 3 + w 4 w ˙ 5 = 1 ⋅ w ˙ 3 + 1 ⋅ w ˙ 4 {\displaystyle {\begin{array}{l|l}{\text{Operations to compute value}}&{\text{Operations to compute derivative}}\\\hline w_{1}=x_{1}&{\dot {w}}_{1}=1{\text{ (seed)}}\\w_{2}=x_{2}&{\dot {w}}_{2}=0{\text{ (seed)}}\\w_{3}=w_{1}\cdot w_{2}&{\dot {w}}_{3}=w_{2}\cdot {\dot {w}}_{1}+w_{1}\cdot {\dot {w}}_{2}\\w_{4}=\sin w_{1}&{\dot {w}}_{4}=\cos w_{1}\cdot {\dot {w}}_{1}\\w_{5}=w_{3}+w_{4}&{\dot {w}}_{5}=1\cdot {\dot {w}}_{3}+1\cdot {\dot {w}}_{4}\end{array}}} この関数 f に対する勾配を求めるためには ∂ y ∂ x 1 {\displaystyle {\tfrac {\partial y}{\partial x_{1}}}} ∂ y ∂ x 2 {\displaystyle {\tfrac {\partial y}{\partial x_{2}}}} w ˙ 1 = 0 ; w ˙ 2 = 1 {\displaystyle {\dot {w}}_{1}=0;{\dot {w}}_{2}=1}
勾配を求める場合に必要なボトムアップ型自動微分の実行回数は入力変数の個数と等しく、トップダウン型自動微分では出力変数の個数に等しい。ボトムアップ型やトップダウン型の自動微分を1回行うのに必要な計算量は、元のプログラムの計算量に比例する。そのため、偏微分する関数f : ℝn m n ≪ m
トップダウン型自動微分では、はじめに偏微分される出力変数を固定して、それぞれの部分式に関する偏導関数値を再帰的に計算する。手計算においては部分式を連鎖律における外側の関数の偏微分で繰り返し置き換えていくことに相当する。
∂ y ∂ x = ∂ y ∂ w 1 ∂ w 1 ∂ x = ( ∂ y ∂ w 2 ∂ w 2 ∂ w 1 ) ∂ w 1 ∂ x = ( ( ∂ y ∂ w 3 ∂ w 3 ∂ w 2 ) ∂ w 2 ∂ w 1 ) ∂ w 1 ∂ x = ⋯ {\displaystyle {\frac {\partial y}{\partial x}}={\frac {\partial y}{\partial w_{1}}}{\frac {\partial w_{1}}{\partial x}}=\left({\frac {\partial y}{\partial w_{2}}}{\frac {\partial w_{2}}{\partial w_{1}}}\right){\frac {\partial w_{1}}{\partial x}}=\left(\left({\frac {\partial y}{\partial w_{3}}}{\frac {\partial w_{3}}{\partial w_{2}}}\right){\frac {\partial w_{2}}{\partial w_{1}}}\right){\frac {\partial w_{1}}{\partial x}}=\cdots } トップダウン型自動微分において、求める値はボトムアップ型の随伴 [訳語疑問点 であり、上線 w ¯ i {\displaystyle {\bar {w}}_{i}} w i {\displaystyle w_{i}}
w ¯ i = ∂ y ∂ w i {\displaystyle {\bar {w}}_{i}={\frac {\partial y}{\partial w_{i}}}} である。連鎖律より、 w i {\displaystyle w_{i}} y ¯ {\displaystyle {\bar {y}}}
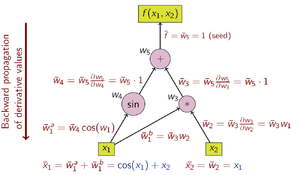
w ¯ i = ∑ j w ¯ j ∂ w j ∂ w i {\displaystyle {\bar {w}}_{i}=\sum _{j}{\bar {w}}_{j}{\frac {\partial w_{j}}{\partial w_{i}}}} トップダウン型自動微分は連鎖律を外側から内側(図3の計算グラフでは上から下)にたどっていく。
偏微分する関数f : ℝn m n ≫ m
しかし、トップダウン型自動微分は、テープやWengert リスト[ 6] [ 4] w i {\displaystyle w_{i}}
図3: トップダウン型自動微分の計算グラフの例 トップダウン型自動微分を用いて偏導関数値を計算するための演算は以下の通りである(関数値を求める時と順番が逆であることに注意)。 w ¯ 1 = ∂ y ∂ x 1 {\displaystyle {\bar {w}}_{1}={\tfrac {\partial y}{\partial x_{1}}}} w ¯ 2 = ∂ y ∂ x 2 {\displaystyle {\bar {w}}_{2}={\tfrac {\partial y}{\partial x_{2}}}}
Operations to compute derivative w ¯ 5 = 1 (seed) w ¯ 4 = w ¯ 5 ⋅ 1 w ¯ 3 = w ¯ 5 ⋅ 1 w ¯ 2 = w ¯ 3 ⋅ w 1 w ¯ 1 = w ¯ 3 ⋅ w 2 + w ¯ 4 ⋅ cos w 1 {\displaystyle {\begin{array}{l}{\text{Operations to compute derivative}}\\\hline {\bar {w}}_{5}=1{\text{ (seed)}}\\{\bar {w}}_{4}={\bar {w}}_{5}\cdot 1\\{\bar {w}}_{3}={\bar {w}}_{5}\cdot 1\\{\bar {w}}_{2}={\bar {w}}_{3}\cdot w_{1}\\{\bar {w}}_{1}={\bar {w}}_{3}\cdot w_{2}+{\bar {w}}_{4}\cdot \cos w_{1}\end{array}}} 最後の w 1 ¯ {\displaystyle {\bar {w_{1}}}} x 1 = w 1 {\displaystyle x_{1}=w_{1}} w 3 {\displaystyle w_{3}} w 4 {\displaystyle w_{4}} w 3 {\displaystyle w_{3}} w 4 {\displaystyle w_{4}} w 1 {\displaystyle w_{1}} w 1 ¯ = w 3 ¯ ∂ w 3 ∂ w 1 + w 4 ¯ ∂ w 4 ∂ w 1 {\displaystyle {\bar {w_{1}}}={\bar {w_{3}}}{\frac {\partial w_{3}}{\partial w_{1}}}+{\bar {w_{4}}}{\frac {\partial w_{4}}{\partial w_{1}}}} w 3 {\displaystyle w_{3}} w 4 {\displaystyle w_{4}}
テープを使用しない場合は、以下のように Python で実装できる。
import math
class Var :
def __init__ ( self , value , children = None ):
self . value = value
self . children = children or []
self . grad = 0
def __add__ ( self , other ):
return Var ( self . value + other . value , [( 1 , self ), ( 1 , other )])
def __mul__ ( self , other ):
return Var ( self . value * other . value , [( other . value , self ), ( self . value , other )])
def sin ( self ):
return Var ( math . sin ( self . value ), [( math . cos ( self . value ), self )])
def calc_grad ( self , grad = 1 ):
self . grad += grad
for coef , child in self . children :
child . calc_grad ( grad * coef )
# 例: f(x, y) = x * y + sin(x)
x = Var ( 2 )
y = Var ( 3 )
f = x * y + x . sin ()
# 偏微分の計算
f . calc_grad ()
print ( "f =" , f . value )
print ( "∂f/∂x =" , x . grad )
print ( "∂f/∂y =" , y . grad )
テープを使用する場合のアルゴリズムの実装の流れは以下の通りである。
テープをサイズ変更が可能な動的配列 として用意する。テープの要素は中間変数 w i {\displaystyle w_{i}} 計算内容(足し算や掛け算など) 計算グラフの入辺:計算に使用した引数のテープ上のインデックスのリスト。 w 3 {\displaystyle w_{3}} w 1 {\displaystyle w_{1}} w 2 {\displaystyle w_{2}} 計算グラフの出辺:この中間変数がどの計算で使われたかのテープ上のインデックスのリスト。計算しながら追記していく。 w 1 {\displaystyle w_{1}} w 3 {\displaystyle w_{3}} w 4 {\displaystyle w_{4}} w i {\displaystyle w_{i}} w ¯ i {\displaystyle {\bar {w}}_{i}} w i {\displaystyle w_{i}} テープの最後の w ¯ i {\displaystyle {\bar {w}}_{i}} w ¯ i = ∑ j w ¯ j ∂ w j ∂ w i {\displaystyle {\bar {w}}_{i}=\sum _{j}{\bar {w}}_{j}{\frac {\partial w_{j}}{\partial w_{i}}}}
スカラー値ではなく NumPy のような多次元配列(テンソル)を扱う場合も処理すべき内容は同じである。 w ¯ j ∂ w j ∂ w i {\displaystyle {\bar {w}}_{j}{\tfrac {\partial w_{j}}{\partial w_{i}}}} [ 7] [ 8] [ 9] [ 10] 行列積 の VJP は行列積で実装できる。ただし、ある軸での和(NumPyのsum)の VJP は、その軸で値を繰り返して w ¯ j {\displaystyle {\bar {w}}_{j}} ハーバード大学 の HIPS が開発していた Autograd[ 11] ∂ w i ∂ w j w ˙ j {\displaystyle {\tfrac {\partial w_{i}}{\partial w_{j}}}{\dot {w}}_{j}}
行列積の vector-Jacobian product (VJP) は、以下のように求める。 Z = X Y {\displaystyle Z=XY} X ¯ {\displaystyle {\bar {X}}}
z i k = ∑ j x i j y j k {\displaystyle z_{ik}=\sum _{j}x_{ij}y_{jk}} 行列積はかけ算して足し算をするが、足し算のトップダウン型自動微分は z ¯ {\displaystyle {\bar {z}}} z ¯ {\displaystyle {\bar {z}}} x ¯ i j {\displaystyle {\bar {x}}_{ij}}
x ¯ i j = ∑ k z ¯ i k y j k {\displaystyle {\bar {x}}_{ij}=\sum _{k}{\bar {z}}_{ik}y_{jk}} これを要素表記から行列表記に直すと、転置行列 との行列積になる。
X ¯ = Z ¯ Y T {\displaystyle {\bar {X}}={\bar {Z}}Y^{T}} 同様に、 y ¯ j k = ∑ i x i j z ¯ i k {\displaystyle {\bar {y}}_{jk}=\sum _{i}x_{ij}{\bar {z}}_{ik}} Y ¯ = X T Z ¯ {\displaystyle {\bar {Y}}=X^{T}{\bar {Z}}}
畳み込みニューラルネットワーク のバイアス項無しの2次元畳み込み(Conv2d[ 12] X ( H in , W in , C in ) {\displaystyle \mathbf {X} (H_{\text{in}},W_{\text{in}},C_{\text{in}})} K ( H kernel , W kernel , C in , C out ) {\displaystyle \mathbf {K} (H_{\text{kernel}},W_{\text{kernel}},C_{\text{in}},C_{\text{out}})} Y ( H out , W out , C out ) {\displaystyle \mathbf {Y} (H_{\text{out}},W_{\text{out}},C_{\text{out}})}
Y ( i , j , n ) = ∑ k , l , m K ( k , l , m , n ) X ( i + k , j + l , m ) {\displaystyle \mathbf {Y} (i,j,n)=\sum _{k,l,m}\mathbf {K} (k,l,m,n)\mathbf {X} (i+k,j+l,m)} 行列積と同じくこれも積和演算なので、 K ¯ {\displaystyle {\bar {\mathbf {K} }}}
K ¯ ( k , l , m , n ) = ∑ i , j Y ¯ ( i , j , n ) X ( i + k , j + l , m ) {\displaystyle {\bar {\mathbf {K} }}(k,l,m,n)=\sum _{i,j}{\bar {\mathbf {Y} }}(i,j,n)\mathbf {X} (i+k,j+l,m)} X ¯ {\displaystyle {\bar {\mathbf {X} }}} X ¯ = 0 {\displaystyle {\bar {\mathbf {X} }}=0}
for
i
,
j
,
k
,
l
,
m
,
n
{\displaystyle i,j,k,l,m,n}
in それぞれの値域
X
¯
(
i
+
k
,
j
+
l
,
m
)
{\displaystyle {\bar {\mathbf {X} }}(i+k,j+l,m)}
K
(
k
,
l
,
m
,
n
)
Y
¯
(
i
,
j
,
n
)
{\displaystyle \mathbf {K} (k,l,m,n){\bar {\mathbf {Y} }}(i,j,n)}
数式で書くと X ¯ ( p , q , m ) = ∑ i , j , k , l , n K ( k , l , m , n ) Y ¯ ( i , j , n ) , where i + k = p ∧ j + l = q {\displaystyle {\bar {\mathbf {X} }}(p,q,m)=\sum _{i,j,k,l,n}\mathbf {K} (k,l,m,n){\bar {\mathbf {Y} }}(i,j,n),{\text{ where }}i+k=p\land j+l=q}
バイアス項 B {\displaystyle \mathbf {B} } Y ( i , j , k ) = X ( i , j , k ) + B ( k ) {\displaystyle \mathbf {Y} (i,j,k)=\mathbf {X} (i,j,k)+\mathbf {B} (k)} X ¯ ( i , j , k ) = Y ¯ ( i , j , k ) {\displaystyle {\bar {\mathbf {X} }}(i,j,k)={\bar {\mathbf {Y} }}(i,j,k)} B ¯ ( k ) = ∑ i , j Y ¯ ( i , j , k ) {\displaystyle {\bar {\mathbf {B} }}(k)=\sum _{i,j}{\bar {\mathbf {Y} }}(i,j,k)}
畳み込みニューラルネットワーク のカーネルの大きさが(p,q)の2次元最大値プーリング(MaxPool2d[ 13]
Y ( i , j , m ) = max k , l X ( p i + k , q j + l , m ) {\displaystyle \mathbf {Y} (i,j,m)=\max _{k,l}\mathbf {X} (pi+k,qj+l,m)} これの X ¯ {\displaystyle {\bar {\mathbf {X} }}} Y ¯ {\displaystyle {\bar {\mathbf {Y} }}}
X ¯ ( p i + k , q j + l , m ) = { Y ¯ ( i , j , m ) if ( k , l ) = a r g m a x k , l X ( p i + k , q j + l , m ) 0 otherwise {\displaystyle {\bar {\mathbf {X} }}(pi+k,qj+l,m)={\begin{cases}{\bar {\mathbf {Y} }}(i,j,m)&{\text{if }}(k,l)=\mathop {\rm {argmax}} \limits _{k,l}\mathbf {X} (pi+k,qj+l,m)\\0&{\text{otherwise}}\end{cases}}}
ReLU 畳み込みニューラルネットワークの活性化関数 の ReLU は要素表記では Y ( i , j , k ) = max { 0 , X ( i , j , k ) } {\displaystyle \mathbf {Y} (i,j,k)=\max\{0,\mathbf {X} (i,j,k)\}} X ¯ {\displaystyle {\bar {\mathbf {X} }}} X ≥ 0 {\displaystyle \mathbf {X} \geq 0} Y ¯ {\displaystyle {\bar {\mathbf {Y} }}}
X ¯ ( i , j , k ) = { Y ¯ ( i , j , k ) if X ( i , j , k ) ≥ 0 0 otherwise {\displaystyle {\bar {\mathbf {X} }}(i,j,k)={\begin{cases}{\bar {\mathbf {Y} }}(i,j,k)&{\text{if }}\mathbf {X} (i,j,k)\geq 0\\0&{\text{otherwise}}\end{cases}}}
ボトムアップ型自動微分は実数 の代数 に(元を)添加して新しい算術 を導入することによって可能である。全ての数(通常の実数)に対して、その数における関数の微分を表現する追加の成分が足され、全ての算術演算がこの添加代数に拡張される。すなわち二重数 の代数である。このアプローチはプログラミング空間上の演算子法(英語版) の理論(つまり双対空間 のテンソル代数 )によって一般化される(解析的プログラミング空間(英語版) を見よ)。
各数 x {\displaystyle x} x + x ′ ε {\displaystyle x+x'\varepsilon } x ′ {\displaystyle x'} ε {\displaystyle \varepsilon } ε 2 = 0 {\displaystyle \varepsilon ^{2}=0} 抽象的数(英語版) である(無限小 ;滑らかな無限小解析 も参照)。ちょうどこれだけを用いて通常の演算が得られる:
( x + x ′ ε ) + ( y + y ′ ε ) = x + y + ( x ′ + y ′ ) ε ( x + x ′ ε ) ⋅ ( y + y ′ ε ) = x y + x y ′ ε + y x ′ ε + x ′ y ′ ε 2 = x y + ( x y ′ + y x ′ ) ε {\displaystyle {\begin{aligned}(x+x'\varepsilon )+(y+y'\varepsilon )&=x+y+(x'+y')\varepsilon \\(x+x'\varepsilon )\cdot (y+y'\varepsilon )&=xy+xy'\varepsilon +yx'\varepsilon +x'y'\varepsilon ^{2}=xy+(xy'+yx')\varepsilon \end{aligned}}} 引き算と割り算についても同様である。
いまやこの拡張算術のもとで多項式 を計算できる。もし P ( x ) = p 0 + p 1 x + p 2 x 2 + ⋯ + p n x n {\displaystyle P(x)=p_{0}+p_{1}x+p_{2}x^{2}+\cdots +p_{n}x^{n}}
P ( x + x ′ ε ) = p 0 + p 1 ( x + x ′ ε ) + ⋯ + p n ( x + x ′ ε ) n = p 0 + p 1 x + ⋯ + p n x n + p 1 x ′ ε + 2 p 2 x x ′ ε + ⋯ + n p n x n − 1 x ′ ε = P ( x ) + P ( 1 ) ( x ) x ′ ε {\displaystyle {\begin{aligned}P(x+x'\varepsilon )&=p_{0}+p_{1}(x+x'\varepsilon )+\cdots +p_{n}(x+x'\varepsilon )^{n}\\&=p_{0}+p_{1}x+\cdots +p_{n}x^{n}+p_{1}x'\varepsilon +2p_{2}xx'\varepsilon +\cdots +np_{n}x^{n-1}x'\varepsilon \\&=P(x)+P^{(1)}(x)x'\varepsilon \end{aligned}}}
ここで P ( 1 ) {\displaystyle P^{(1)}} P {\displaystyle P} x ′ {\displaystyle x'}
上に述べたように、この新しい算術は、順序対 ( ⟨ x , x ′ ⟩ {\displaystyle \langle x,x'\rangle } 解析関数 に広げれば、新しい算術に対する、基本的な算術と幾つかの標準的な関数のリストが得られる:
⟨ u , u ′ ⟩ + ⟨ v , v ′ ⟩ = ⟨ u + v , u ′ + v ′ ⟩ ⟨ u , u ′ ⟩ − ⟨ v , v ′ ⟩ = ⟨ u − v , u ′ − v ′ ⟩ ⟨ u , u ′ ⟩ ∗ ⟨ v , v ′ ⟩ = ⟨ u v , u ′ v + u v ′ ⟩ ⟨ u , u ′ ⟩ / ⟨ v , v ′ ⟩ = ⟨ u v , u ′ v − u v ′ v 2 ⟩ ( v ≠ 0 ) sin ⟨ u , u ′ ⟩ = ⟨ sin ( u ) , u ′ cos ( u ) ⟩ cos ⟨ u , u ′ ⟩ = ⟨ cos ( u ) , − u ′ sin ( u ) ⟩ exp ⟨ u , u ′ ⟩ = ⟨ exp u , u ′ exp u ⟩ log ⟨ u , u ′ ⟩ = ⟨ log ( u ) , u ′ / u ⟩ ( u > 0 ) ⟨ u , u ′ ⟩ k = ⟨ u k , k u k − 1 u ′ ⟩ ( u ≠ 0 ) | ⟨ u , u ′ ⟩ | = ⟨ | u | , u ′ sign u ⟩ ( u ≠ 0 ) {\displaystyle {\begin{aligned}\left\langle u,u'\right\rangle +\left\langle v,v'\right\rangle &=\left\langle u+v,u'+v'\right\rangle \\\left\langle u,u'\right\rangle -\left\langle v,v'\right\rangle &=\left\langle u-v,u'-v'\right\rangle \\\left\langle u,u'\right\rangle *\left\langle v,v'\right\rangle &=\left\langle uv,u'v+uv'\right\rangle \\\left\langle u,u'\right\rangle /\left\langle v,v'\right\rangle &=\left\langle {\frac {u}{v}},{\frac {u'v-uv'}{v^{2}}}\right\rangle \quad (v\neq 0)\\\sin \left\langle u,u'\right\rangle &=\left\langle \sin(u),u'\cos(u)\right\rangle \\\cos \left\langle u,u'\right\rangle &=\left\langle \cos(u),-u'\sin(u)\right\rangle \\\exp \left\langle u,u'\right\rangle &=\left\langle \exp u,u'\exp u\right\rangle \\\log \left\langle u,u'\right\rangle &=\left\langle \log(u),u'/u\right\rangle \quad (u>0)\\\left\langle u,u'\right\rangle ^{k}&=\left\langle u^{k},ku^{k-1}u'\right\rangle \quad (u\neq 0)\\\left|\left\langle u,u'\right\rangle \right|&=\left\langle \left|u\right|,u'{\mbox{sign}}u\right\rangle \quad (u\neq 0)\end{aligned}}} 一般に、プリミティヴの関数 g {\displaystyle g}
g ( ⟨ u , u ′ ⟩ , ⟨ v , v ′ ⟩ ) = ⟨ g ( u , v ) , g u ( u , v ) u ′ + g v ( u , v ) v ′ ⟩ {\displaystyle g(\langle u,u'\rangle ,\langle v,v'\rangle )=\langle g(u,v),g_{u}(u,v)u'+g_{v}(u,v)v'\rangle } ここで g u {\displaystyle g_{u}} g v {\displaystyle g_{v}} g {\displaystyle g}
基本的な二項算術演算を(実数と二重数の)混在した引数に対して、つまり順序対 ⟨ u , u ′ ⟩ {\displaystyle \langle u,u'\rangle } c {\displaystyle c} ⟨ c , 0 ⟩ {\displaystyle \langle c,0\rangle } f : R → R {\displaystyle f:\mathbb {R} \rightarrow \mathbb {R} } x 0 {\displaystyle x_{0}} f ( ⟨ x 0 , 1 ⟩ ) {\displaystyle f(\langle x_{0},1\rangle )} ⟨ f ( x 0 ) , f ′ ( x 0 ) ⟩ {\displaystyle \langle f(x_{0}),f'(x_{0})\rangle }
多変数関数は、方向微分作用素を用いることで、一変数関数の場合と同様の効率と仕組みで取り扱える。つまり、 f : R n → R m {\displaystyle f:\mathbb {R} ^{n}\rightarrow \mathbb {R} ^{m}} x ∈ R n {\displaystyle x\in \mathbb {R} ^{n}} x ′ ∈ R n {\displaystyle x'\in \mathbb {R} ^{n}} y ′ = ∇ f ( x ) ⋅ x ′ {\displaystyle y'=\nabla f(x)\cdot x'} ( ⟨ y 1 , y 1 ′ ⟩ , … , ⟨ y m , y m ′ ⟩ ) = f ( ⟨ x 1 , x 1 ′ ⟩ , … , ⟨ x n , x n ′ ⟩ ) {\displaystyle (\langle y_{1},y'_{1}\rangle ,\ldots ,\langle y_{m},y'_{m}\rangle )=f(\langle x_{1},x'_{1}\rangle ,\ldots ,\langle x_{n},x'_{n}\rangle )} ∇ f {\displaystyle \nabla f} n {\displaystyle n}
上の算術は多変数関数の二階やもっと高階の微分の計算の為に一般化出来る。しかし、その算術規則は直ちに極めて複雑なものとなる:複雑性は最高次の微分の次数に対して二次関数的となる。その代わりに、途中で打ち切った(truncated)テイラー多項式の代数を使用できる。結果得られる算術(一般化された二重数の上で定義された)は、関数を新しいデータ型であるかのように使って、効率的に計算することを可能にする。ひとたび関数のテイラー多項式が分かれば、その導関数たちは容易に抽出できる。 厳密で一般的な定式化はテンソル級数展開(英語版) を通してプログラミング空間上の演算子法(英語版) を用いることにより達成される。
自動微分の実装方法には大きく分けて、ソースコードの変換とオペレータオーバーローディングによる方法の2つがある。
図4: ソースコード変換の動作例 関数値を求める関数を記述した元のソースコードから、偏導関数値を計算する処理を含んだプログラムを自動的に生成する手法である。ソースコード変換はあらゆるプログラミング言語で実装でき、コンパイル時の最適化を行いやすいが、自動微分ツールの作成は難しい。
図5: オペレータオーバーローディングの動作例 この手法は演算子のオーバーロードがサポートされているプログラミング言語で記述されたソースコードに対してのみ適用可能である。元のソースコードの流れを大きく変更することなく実現できるが、基本データ型の変更などの小さな変更は必要である。
ボトムアップ型自動微分をオペレータオーバーロードで実現するのは容易である。トップダウン型自動微分についても可能であるが、現状のコンパイラではボトムアップ型自動微分と比べると最適化の面で不利である。
自動微分を実装したライブラリなどのソフトウェアが多数存在する。2010年代の第3次人工知能ブームの際にディープラーニング に自動微分が必要なため、TensorFlow やPyTorch などトップダウン型の自動微分を含むライブラリが多数作られた。
^ a b Automatic Differentiation in Machine Learning: a Survey ^ 連鎖律(多変数関数の合成関数の微分) | 高校数学の美しい物語 ^ 合成関数の偏微分における連鎖律(チェインルール)とその証明 | 数学の景色 ^ a b R.E. Wengert (1964). “A simple automatic derivative evaluation program”. Comm. ACM 7 : 463–464. doi:10.1145/355586.364791. https://dl.acm.org/doi/10.1145/355586.364791 . ^ Andreas Griewank (2012). “Who Invented the Reverse Mode of Differentiation”. Optimization Stories, Documenta Matematica Extra Volume ISMP : 389–400. https://www.math.uni-bielefeld.de/documenta/vol-ismp/52_griewank-andreas-b.pdf . ^ Bartholomew-Biggs, Michael; Brown, Steven; Christianson, Bruce; Dixon, Laurence (2000). “Automatic differentiation of algorithms”. Journal of Computational and Applied Mathematics 124 (1-2): 171-190. doi:10.1016/S0377-0427(00)00422-2. https://www.sciencedirect.com/science/article/pii/S0377042700004222 . ^ autograd/tutorial.md at master · HIPS/autograd ^ Derivatives in Theano — Theano 1.1.2+29.g8b2825658.dirty documentation ^ 2104.00219 Fast Jacobian-Vector Product for Deep Networks ^ Pearlmutter, Barak A. (1994-01-01). “Fast Exact Multiplication by the Hessian”. Neural Computation 6 (1): 147-160. doi:10.1162/neco.1994.6.1.147. ^ HIPS/autograd: Efficiently computes derivatives of numpy code. ^ “Conv2d — PyTorch 2.3 documentation”. pytorch.org . 2 July 2024 閲覧。 ^ “MaxPool2d — PyTorch 2.3 documentation”. pytorch.org . 6 July 2024 閲覧。
久保田, 光一; 伊理, 正夫 (1998). アルゴリズムの自動微分と応用 . 現代非線形科学シリーズ. 3 . コロナ社. ISBN 978-4339026023 伊理正夫、「高速自動微分法(第2回年会特別講演)」『応用数理』 1993年 3巻 1号 p.58-66, doi:10.11540/bjsiam.3.1_58, 日本応用数理学会 Rall, Louis B. (1981). Automatic Differentiation: Techniques and Applications . Lecture Notes in Computer Science. 120 . Springer . ISBN 3-540-10861-0 Griewank, Andreas; Walther, Andrea (2008). Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation . Other Titles in Applied Mathematics. 105 (2nd ed.). SIAM. ISBN 978-0-89871-659-7. http://www.ec-securehost.com/SIAM/OT105.html Neidinger, Richard (2010). “Introduction to Automatic Differentiation and MATLAB Object-Oriented Programming”. SIAM Review 52 (3): 545–563. doi:10.1137/080743627. http://academics.davidson.edu/math/neidinger/SIAMRev74362.pdf 2013年3月15日 閲覧。
www.autodiff.org - Community Portal for Automatic Differentiation 典拠管理データベース: 国立図書館










































































































 自動微分
自動微分